中文



作(zuò)者:謝湘甯
摘要:當代是科(kē)學技術(shù)迅猛發展的時代,專利信息作(zuò)爲獲取技術(shù)創新以及商業競争主動權的情報信息,專利信息的研究成爲當務之急。本文将數據挖掘技術(shù)應用到專利信息的分(fēn)析當中,爲企業的技術(shù)競争和商業競争提供有效的措施和手段,使其成爲支持企業決策的有效依據。
關鍵字:專利信息、數據挖掘、決策依據
一、引言
随着當前科(kē)學技術(shù)和知識經濟的飛速發展,企業之間的知識競争日(rì)趨激烈,經研究者發現,企業間的競争可(kě)以通過所擁有的自(zì)主知識産權來(lái)集中體(tǐ)現,特别是專利的數量和質量的競争[1]。而在企業擁有了海量的專利之後,如(rú)何從(cóng)海量的專利信息中理(lǐ)性的獲取隐含的情報信息,挖掘出專利的潛在價值,使其成爲企業決策過程中的有效依據将是一個巨大(dà)的挑戰。在這樣的背景形勢之下,專利分(fēn)析(Patent Analysis)作(zuò)爲一種獨特而實用的分(fēn)析方法,可(kě)以爲企業提供有效的企業競争情報[2]。
傳統的專利信息的分(fēn)析方法主要包括原文分(fēn)析法和數據統計(jì)等方法,即通過專利文獻上所固有的指标數據(如(rú)專利申請(qǐng)号等)來(lái)識别相(xiàng)關文獻,然後對指标數據進行統計(jì)以取得(de)動态發展趨勢的分(fēn)析報告。由于這種傳統的分(fēn)析方法沒有建立在專利本身(shēn)潛藏的知識體(tǐ)系上,因此,面對大(dà)量的專利文獻數據時,不僅工(gōng)作(zuò)量繁巨,而且對專利文獻的應用也隻停留在表層,導緻分(fēn)析不夠透徹。
而數據挖掘技術(shù)可(kě)以從(cóng)大(dà)量雜亂無章(zhāng)的、無法通過人(rén)工(gōng)進行統計(jì)的數據中發掘出潛在的信息,而且還(hái)可(kě)以通過計(jì)算機(jī)手段将潛在的關系進行構建,呈獻給人(rén)們以示規律,因此,數據挖掘技術(shù)将是優先考慮的專利分(fēn)析技術(shù)[3]。
本文采用數據挖掘技術(shù)來(lái)代替現有的傳統分(fēn)析方法,獲取海量專利數據中原來(lái)無法挖掘到的内容和規律。同時采用合适的模型和參數,真正發揮數據挖掘技術(shù)應用在專利分(fēn)析中的作(zuò)用[4]。
二、 數據挖掘技術(shù)在專利信息分(fēn)析中的技術(shù)與實現
本文章(zhāng)将數據挖掘作(zuò)爲一個專利分(fēn)析的強有力的工(gōng)具被引入到專利分(fēn)析中來(lái),主要通過有效的數學模型來(lái)對選擇的專利信息的數據進行詳細分(fēn)析和處理(lǐ),更深層次的對專利信息進行有效的分(fēn)析和挖掘,從(cóng)而可(kě)以深入、充分(fēn)而且有效的挖掘出隐藏在大(dà)量專利信息背後的重要知識。進一步可(kě)以解決例如(rú)專利預警和警情分(fēn)析中存在的問(wèn)題,例如(rú),在某一個産品進入市場尤其進入國(guó)際市場之後,将不可(kě)避免遭遇國(guó)際知名産品在某一些技術(shù)方面的競争和阻擊,通過數據挖掘技術(shù)可(kě)以針對該産品相(xiàng)關的專利信息進行分(fēn)析和處理(lǐ),即挖掘和分(fēn)析高風(fēng)險技術(shù)的專利情況,從(cóng)而盡早避免可(kě)能發生(shēng)的侵權争端。
1. 專利信息的來(lái)源及分(fēn)類
本文利用專利數據庫平台作(zuò)爲數據采集源,采集相(xiàng)關的專利樣本,例如(rú),可(kě)以通過專利搜索引擎(例如(rú)http://www.soopat.com/)篩選一定數量的、已經公開的發明專利文獻。
本文在利用數據挖掘技術(shù)對專利文獻進行分(fēn)析之前,可(kě)以按照(zhào)專利文獻的分(fēn)類号對專利文獻進行分(fēn)類。國(guó)際專利分(fēn)類法(IPC) 是目前最爲權威、應用最廣的專利技術(shù)主題标識編碼之一,它具有編排合理(lǐ)且通用性好的特點[5]。由于過于細緻的IPC分(fēn)類号對專利文檔主題的揭示并不有利,因此,研究者認爲采用專利文獻的專利小類作(zuò)爲分(fēn)析基礎,例如(rú)取專利文獻IPC分(fēn)類号的前4位。
2. 對分(fēn)類後的專利文獻進行數據訓練
由于專利文獻是文本格式類型的文件(jiàn),爲了能夠把數據挖掘技術(shù),例如(rú)聚類技術(shù)應用到文本格式類型的文獻中,需要對文本格式的文獻進行數據訓練,數據訓練用于實現對真實的專利文獻進行文本的預處理(lǐ),包括對專利文獻進行分(fēn)詞、關鍵詞訓練和提取,以及對關鍵詞的權重計(jì)算,其中,關鍵詞訓練和提取主要包括詞性标注和停用詞過濾。
(1)專利信息的分(fēn)詞處理(lǐ)
需要對分(fēn)類後的專利文獻進行分(fēn)詞處理(lǐ),從(cóng)而獲取到每個專利文獻中的若幹關鍵詞,專利文獻中的這些關鍵詞用于表征當前專利申請(qǐng)的主要核心技術(shù)、主要用途的詞或短(duǎn)語。
此處需要重點說(shuō)明的是,由于中文語句的特點是在一句完整的語句中無法通過空格将詞彙分(fēn)割,因此,分(fēn)詞技術(shù)主要針對中文文本的專利文獻,分(fēn)詞策略可(kě)以包括:按照(zhào)掃描方向的不同可(kě)以分(fēn)爲正相(xiàng)匹配和逆向匹配的分(fēn)詞策略;按照(zhào)字符串的不同長度的優先策略可(kě)以分(fēn)爲最大(dà)匹配和最小匹配的分(fēn)詞策略;按照(zhào)是否有詞性标注的方式,可(kě)以分(fēn)爲單純分(fēn)詞和分(fēn)詞與标注相(xiàng)結合的分(fēn)詞策略。分(fēn)詞技術(shù)可(kě)以将文檔詞彙化,爲關鍵詞訓練作(zuò)基礎。
而針對英文語句,由于英文單詞之間一般采用空格隔開,從(cóng)而使得(de)英文語句無需進行分(fēn)詞處理(lǐ),但(dàn)需要對英文專利文獻進行剔除和整合詞語的預處理(lǐ)。在英文專利文獻中,類似于an、the、that、first等介詞、連詞、數量詞屬于沒有特殊标注性含義的停用詞,在文本挖掘不具備關鍵術(shù)語的特征,因此,在英文專利文獻的文本預處理(lǐ)過程中需要剔除停用詞。另外,由于英文詞彙中某個詞語可(kě)能存在大(dà)量變形和時态的變化,一個詞語變形後的多個詞彙表征的含義相(xiàng)同或相(xiàng)似,也不具備關鍵術(shù)語的特性,因此,在英文專利文獻的文本預處理(lǐ)過程中需要将具有相(xiàng)同或相(xiàng)似含義的詞句進行整合。經文本聚類分(fēn)析領域的一些專家研究發現,文本預處理(lǐ)過程中提取的關鍵詞通常隻包括名詞或名詞性短(duǎn)語的概率較大(dà)。
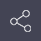
以申請(qǐng)号爲200910092794.8的專利爲例,如(rú)圖1所示,系統在自(zì)動加載了原始的摘要和用途字段之後,可(kě)以自(zì)動進行分(fēn)詞處理(lǐ),提取并顯示關鍵詞。
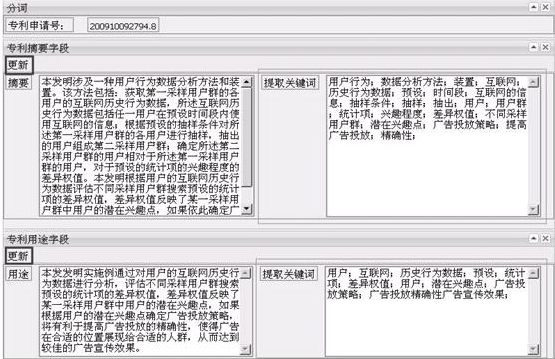
圖1 分(fēn)詞界面示意圖
(2)關鍵詞訓練
爲了将專利文獻轉化爲計(jì)算機(jī)可(kě)以處理(lǐ)的信息,需要對分(fēn)詞處理(lǐ)有的專利文獻進行關鍵詞訓練,關鍵詞訓練的主要目的是爲了提取有代表性的詞彙,以便于生(shēng)成專利文檔的可(kě)以表征文檔特性的向量,本質上就(jiù)是将無結構的原始文章(zhāng)進行科(kē)學抽象,建立數學模型,用結構化的語言表征文檔本身(shēn)。目前人(rén)們通常采用向量空間模型來(lái)描述文本,用特征向量來(lái)表示文檔本身(shēn)。
由上可(kě)知,上述針對專利文獻的數據訓練過程,通過關鍵詞的頻率及權重确定了每篇專利文獻的特征向量,實現了對海量的專利文獻的分(fēn)類整理(lǐ)和文本預處理(lǐ),完成了爲每個專利文獻爲基礎的源文檔建立唯一的向量表,爲後續的聚類功能提供了有效的數據源。
3. 對專利文獻構成的源數據進行聚類
本文研究的是如(rú)何将根據某一技術(shù)領域的專利信息對涉及到的技術(shù)進行方向劃分(fēn),其實也就(jiù)是聚類。之所以會研究這個問(wèn)題主要在于兩個原因:1) 一個技術(shù)領域的專利太多,人(rén)們可(kě)能關心的僅是某一方向上的關鍵技術(shù),即需要的僅是一個較小方向範圍的内的專利信息,這需要篩選;2) 人(rén)們需要判斷某一篇專利在一個方向内是否又相(xiàng)似的專利,以防止侵權或者重複申請(qǐng),因爲重複申請(qǐng)是無效的。
總之,通過聚類技術(shù)我們可(kě)以将一個領域内的專利案技術(shù)分(fēn)類進行劃分(fēn),同時可(kě)以判斷出一個專利屬于那些個方向,聚焦到一個聚類中分(fēn)析。
數據挖掘領域常用的聚類技術(shù)可(kě)以包括如(rú)下幾種:基本k均值技術(shù)、二分(fēn)k均值技術(shù)、基于密度的DBSCAN聚類、模糊聚類和EM聚類等。
本文利用數據挖掘技術(shù)中的凝聚層次聚類算法,依據餘弦相(xiàng)似度作(zuò)爲聚類合并的依據,對得(de)到的每個專利文獻的文檔向量來(lái)進行聚類,即在對文檔向量集合中的每個文檔向量進行初始化之後,使得(de)若幹個專利文檔作(zuò)爲一個簇類,然後通過凝聚層次聚類算法的到需要合并的簇類,最終得(de)到該文檔向量集合的簇類結果。
4. 專利信息的聚類分(fēn)析結果及其布局圖。
本文利用上述聚類方法聚類得(de)到的聚類數目,分(fēn)别作(zuò)出在該選定數目下的聚類比重圖、曆史變化圖,通過曲線變化和數量對比,從(cóng)而進一步得(de)到某些方向的專利文獻數量趨冷(lěng)還(hái)是趨熱(rè),專利方向的變化如(rú)何,等等非常具有價值的信息。
以2010、2011、2012公開的關于某搜索引擎産品在數據分(fēn)析領域的150篇專利爲例,如(rú)圖2所示, 在确定聚類數目爲10的情況下,對10個聚類當中的具體(tǐ)每一個簇包含多少篇專利文獻進行統計(jì),獲取每個聚類當中所包含的專利文獻數量。

圖2基于簇的專利數量總體(tǐ)分(fēn)布柱形圖
分(fēn)析上圖2中的結果,編号爲3,6,9的聚類,比較其他(tā)聚類專利文獻的數據量占比例最大(dà),以上述3個聚類作(zuò)爲考察對象可(kě)以直觀的确定哪類技術(shù)的專利申請(qǐng)量最多,最集中。
分(fēn)析可(kě)知,3,6,9的聚類中的專利技術(shù)處于成熟期,這些技術(shù)分(fēn)布範圍大(dà),市場占有可(kě)能趨于飽和,專利申請(qǐng)量保持穩定;4,5的聚類中的技術(shù)處于引入期,該搜索引擎産品的廠(chǎng)商在這些領域技術(shù)開發較少,基本屬于原理(lǐ)性和基礎性的專利;1,2,10的聚類中的專利處于技術(shù)發展期,市場在逐步擴大(dà),數量應該是繼續增長。
基于此可(kě)知,如(rú)果該搜索引擎廠(chǎng)商在進軍中國(guó)市場,例如(rú),研發、銷售搜索技術(shù)類産品時,可(kě)以根據上述分(fēn)析結果做出以下對策:主要針對發展期的的專利産品進行大(dà)力改進和開發,針對成熟期的産品則可(kě)以持保守态度,需要時可(kě)以采用向對方進行技術(shù)許可(kě)的策略。
同時,可(kě)以針對聚類結果進行更加深入的聚類評估,評估的目的在于判斷數據集合是否存在于某聚類中和聚類數量的确定,企業可(kě)以利用評估結果解決如(rú)下疑惑:
1)利用凝聚度來(lái)确定專利文獻構成的專利技術(shù)在各個自(zì)然年(nián)的專利數量分(fēn)布情況。
仍舊以上述2010、2011、2012公開的關于某搜索引擎産品在數據分(fēn)析領域的150篇專利爲例,如(rú)圖3所示,統計(jì)上述3年(nián)中,專利數量在3個主要聚類當中的所占數量。
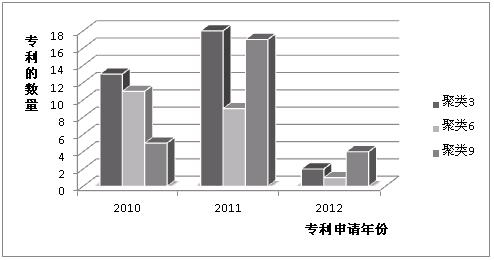
圖3每個聚類的專利數量對比柱形圖
分(fēn)析可(kě)知,2011 是專利總數量最多的一年(nián),并且2010年(nián)的專利數量也保持較高的水平 ,說(shuō)明2011和2010年(nián)的總體(tǐ)專利數量集中在當前的3大(dà)聚類當中。
由于上述簇類3、6、9中的專利可(kě)以認爲是該搜索引擎産品在數據分(fēn)析領域的重點專利,根據圖3的分(fēn)析結果,簇類6中的專利在逐年(nián)減少,可(kě)以推測該類技術(shù)可(kě)能在2013年(nián)進入飽和期,這類技術(shù)快(kuài)要被淘汰;簇類3和9中的專利在2010年(nián)到2011年(nián)大(dà)幅增加,但(dàn)到2012年(nián)大(dà)幅減少,可(kě)以說(shuō)明這類專利從(cóng)快(kuài)速成長期到穩定成熟期的階段。
2) 利用分(fēn)離(lí)度來(lái)确定幾個簇類之間的關聯度,從(cóng)而确定對于海量專利文獻如(rú)何将他(tā)們按照(zhào)内部特征進行分(fēn)離(lí),以供挖掘出一些潛在信息,例如(rú),比對任意兩個或多個自(zì)然年(nián),分(fēn)析得(de)出針對同一個技術(shù)領域的研發能力哪一個自(zì)然年(nián)的研發技術(shù)明顯更強。
仍舊以上述2010、2011、2012公開的關于某搜索引擎産品在數據分(fēn)析領域的150篇專利爲例,如(rú)圖4所示的聚類比例曆史變化圖對應的統計(jì)圖, 研究每個自(zì)然年(nián)中那個聚類的熱(rè)度。
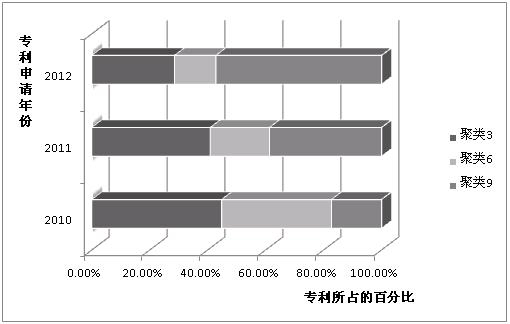
圖4聚類後專利比例變化的統計(jì)圖
分(fēn)析可(kě)知,2010、2011年(nián)聚類3的比例最大(dà),2012年(nián)聚類9的比例最大(dà),由此我們能夠知道,在3個大(dà)的聚類當中:聚類3是2010、2011年(nián)的最熱(rè)門(mén)方向,聚類9是2012年(nián)的最熱(rè)門(mén)方向。
3) 爲了進一步的發掘3個聚類内部的趨冷(lěng)趨熱(rè)程度,可(kě)以将比例變爲縱坐(zuò)标,年(nián)份作(zuò)爲橫坐(zuò)标,做出如(rú)圖5所示的聚類趨勢變化圖。
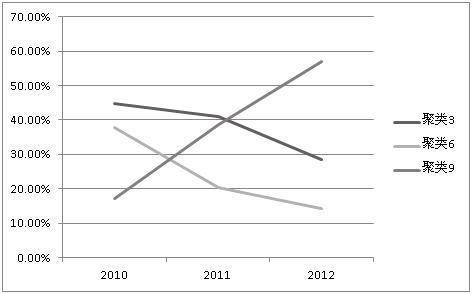
圖5聚類趨勢變化圖
結合圖5分(fēn)析可(kě)知:
聚類3從(cóng)2010年(nián)開始,逐年(nián)申請(qǐng)的專利在比例上較爲持平,下降并不明顯,說(shuō)明該方向技術(shù)研究及開發的熱(rè)度具有一定的持續性。
聚類6從(cóng)2010年(nián)開始,逐年(nián)申請(qǐng)的專利在比例下降得(de)比較明顯,說(shuō)明該方向的技術(shù)研究及開發的熱(rè)度在趨于變冷(lěng)。
聚類9從(cóng)2010年(nián)開始,逐年(nián)申請(qǐng)的專利在比例上上升得(de)非常明顯,說(shuō)明該方向的技術(shù)研究及開發的熱(rè)度在趨于變熱(rè)。
由此可(kě)知,利用聚類評估技術(shù)作(zuò)爲聚類處理(lǐ)的方法,其主要目标是要在海量專利數據中挖掘潛在的、未知的類别體(tǐ)系。
上述分(fēn)析過程還(hái)可(kě)以進一步擴大(dà)到對多家競争企業的專利進行分(fēn)析,可(kě)以獲取哪些公司的專利布局最早出現、在哪些年(nián)份專利申請(qǐng)量最多、專利申請(qǐng)量是階梯式增長還(hái)是減少等信息,然後進行比較,從(cóng)而得(de)到整個行業的技術(shù)發展的分(fēn)析結果,例如(rú),在搜索領域哪些技術(shù)是核心技術(shù),哪些是被淘汰的技術(shù),哪些技術(shù)有更大(dà)的發展空間和投資空間等。
三、結語
本文的分(fēn)析結果是具有實際意義的,對企業進行侵權分(fēn)析建議(yì)(無效、許可(kě)、公衆意見(jiàn)和專利規避)、競争對手跟蹤建議(yì)、市場定位建議(yì)等方面都(dōu)具有實際意義。由于是從(cóng)專利文獻的詞彙本身(shēn)進行分(fēn)析得(de)到的結果,因此,作(zuò)者認爲本文章(zhāng)的方法比現有的方法分(fēn)析結果更準确、指導性更強。
參考文獻
[1] 于和琴,專利情報數據挖掘-企業獲取競争優勢的法寶,商業現代化,2008年(nián)5月.
[2] 黃(huáng)慶,曹津燕,瞿衛軍,劉洋,石昱,肖雲鵬,專利評價指标體(tǐ)系的設計(jì)和構建,知識産權,2003.
[3] 岑詠華,王曰芬,王曉蓉,面向企業技術(shù)創新決策的專利數據玩家研究綜述,情報理(lǐ)論與實踐,第33卷,2010年(nián)第1期.
[4] 柴明亮,關聯規則在時間序列數據挖掘中的應用[D],北京:北京工(gōng)業大(dà)學,2006:23-24.
[5] 劉德馨,李有馥,國(guó)際專利分(fēn)類法評價[J],情報科(kē)學,1993年(nián)04期.